

Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation
KeyWords Plus: CVPR2018 Multi-Oriented Text
paper:https://arxiv.org/pdf/1802.08948.pdf
reference: Lyu P, Yao C, Wu W, et al. Multi-oriented scene text detection via corner localization and region segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 7553-7563.
Github: https://github.com/lvpengyuan/corner
方法概括
方法概述
该方法用一个端到端的网络实现文本检测整个过程。除了基础卷积网络(backbone)外,包括两个并行分支和一个后处理过程。第一个分支是通过一个DSSD网络进行角点检测来提取候选文本区域,第二个分支是利用类似于RFCN进行网格划分的方式来做position-sensitive的segmentation。后处理过程是利用segmentation的score map来综合得分,过滤角点检测得到的候选区域中的噪声。
背景(文本检测三大难点)
- 多方向
- 长宽比多变
- 文本的粒度多样(包括字符、单词、文本行等多种形式)
文章亮点
- 检测不是用一般的object detection的框架来做,而是用corner point detection来做,可以更好地解决文本方向任意、文本长宽比多变的问题。
- 分割用的是position sensitive segmentation,仿照RFCN划分网格的思路,把位置信息融合进去,对于检测单词这种细粒度的更有帮助。
- 把检测和分割两大类的方法整合起来,进行综合打分的pipeline,这可以使检测精度更高。
方法细节
主要流程
用一个检测网络完成整个检测过程,该网络分为以下几个部分: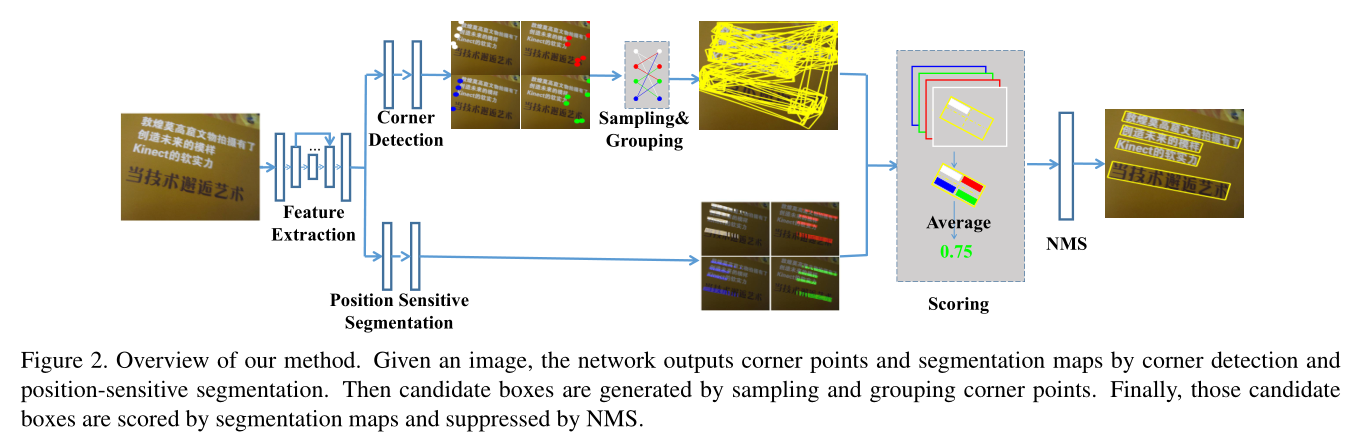
- backbone:基础网络,用于特征提取(不同分支特征共享)。
- corner detection:用来生成候选检测框,是一个独立的检测模块,类似于RPN的功能。
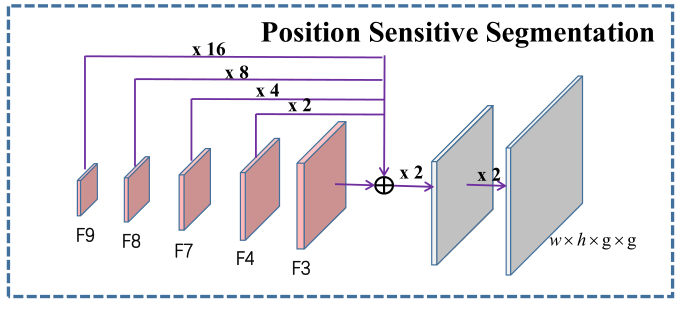
- Position Sensitive Segmentation:整张图逐像素的打分,和一般分割不同的是输出4个score map,分别对应左上、右上、右下、左下四个不同位置的得分。
- Scoring + NMS:综合打分,利用(2)的框和(3)的score map综合打分,去掉非文本框,最后再接一个NMS。
网络结构
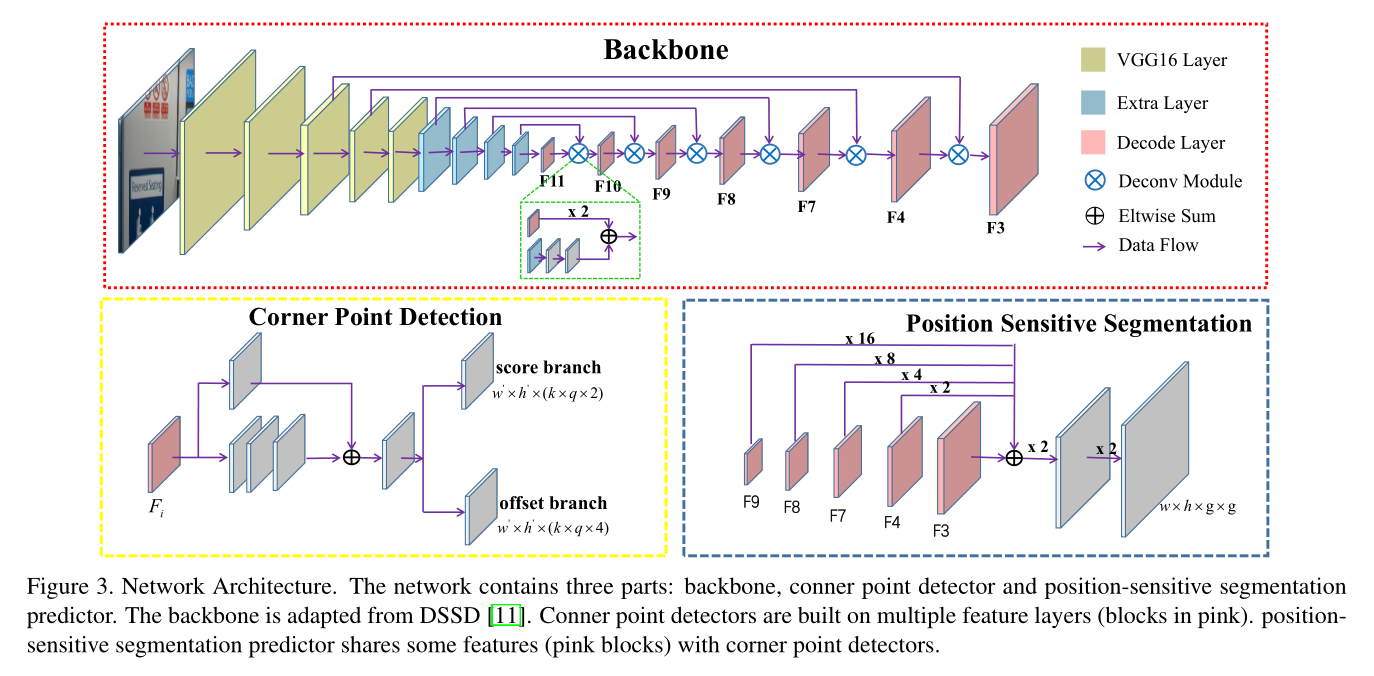
- Backbone取自DSSD = VGG16(pool5) + conv6(fc6) + conv7(fc7) + 4conv + 6 deconv (with 6 residual block)。
- Corner Point Detection是类似于SSD,从多个deconv的feature map上单独做detection得到候选框,然后多层的检测结果串起来,nms后为最后的结果。
- 损失:
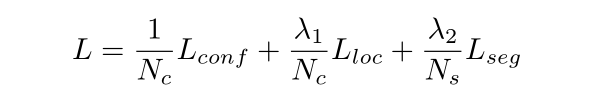
Corner Detection
思路说明
- Step1: 用DSSD框架(任何一个目标检测的框架都可以)找到一个框的四个角点,然后整张图的所有角点都放到一个集合中。
- Step2: 把集合中的所有角点进行组合得到所有候选框。
网络结构
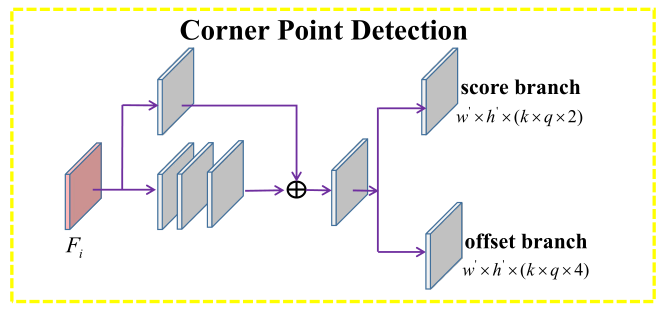
- Fi表示backbone结构中的后面几个deconv得到的feature map(每层都单独做了detection)。
- w, h是feature map大小,k是defalt box的个数,q表示角点类型,这里q = 4,即每个位置(左上、右上、右下、左下)都能单独得到2个score map和4个offset map。
角点信息
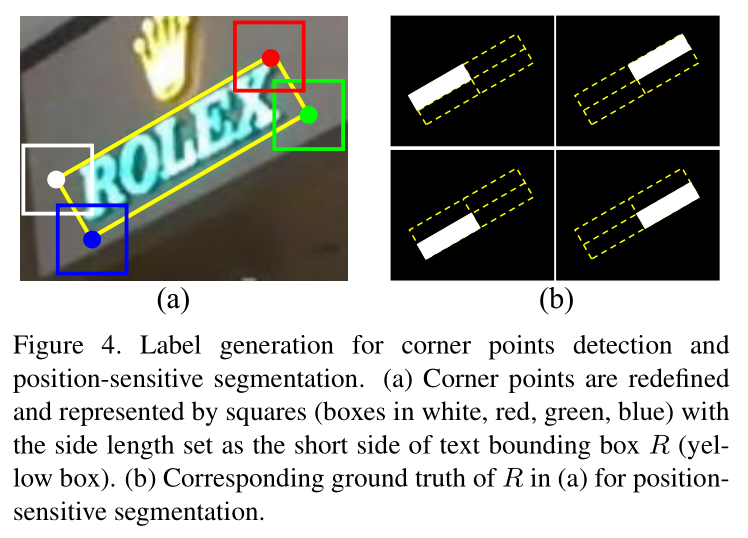
- 实际上是一个正方形,正方形中心为gt框(指的是文本框)的顶点,正方形的边长 = gt框的最短边。
- corner detection对每一种角点(四种)单独输出corner box,可以看做是一个四类的目标检测问题。
角点如何组合成文本框?
- 由于角点不但有顶点位置信息,也有边长信息,所以满足条件的两个corner point组合起来可以确定一个文字框。
- 具体组合思路如下: 一个rotated rectangle可以由两个顶点+垂直于两个顶点组成的边且已知长度的边来确定。
- 由于角点的顶点类型确定,所以短边方向也是确定的,例如左上-左下连边确定短边在右边。
- 垂直的边的长度可以取两个角点的正方形边长的平均值。
- 可以组合的两个corner point满足条件如下:
- 角点分数阈值>0.5;
- 角点的正方形边长大小相似(边长比<1.5);
- 框的顶点类型和位置先验信息(例如,“左上”、“左下”的角点的x应该比“右上”、“右下”小)。
损失
- 得分分支(score branch)的损失:Cross Entropy损失。
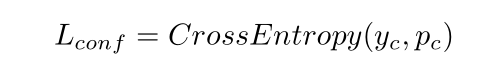
- 偏移分支(offset branch)的损失:Smooth L1损失。
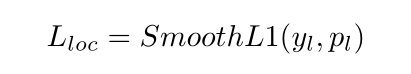
Poosition Sensitive Segmentation
- 思路说明
- 把一个文字框划分成g * g个网格的小框(一个bin),每个bin做为一类,把一个text/non-text的二类问题变成g * g个二类问题。
- 网络结构
- 损失:dice损失
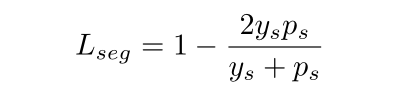
Scoring

- 目的
- 利用segmentation得到的g * g张score map来进一步判断corner detection得到的那些候选框是否是文字,过滤噪声框。
- 思路说明
- 把detection得到的框先划分成g * g个网格(bin),每个bin对应各自的segmentation score map,然后把对应的score map里对应bin位置的那些前景点的像素值取平均(底下P的分母是C,不是直接R的面积,或者bin的面积可以看出只取前景点,即score>0的点)作为每个bin的分数,最后把g * g个bin的分数取平均为初始文字框的分数。
算法伪代码

为什么scoring这么复杂,不直接用区域的像素平均值?
- 采用position sensitive segmentation的思路决定了最后scoring的时候也必须划网格单独取值再平均。至于之所以只取前像素点是为了平均时不受背景点影响,更加精确。
- 注意一点
- 该文章的分割分支与角点分支(也可以叫做回归分支,候选目标检测分支,作用类似于RPN,用来回归候选框)的组合方式与其他的目标检测方法(例如RPN,SSD)中分割与回归分支的组合方式完全不同。对于RPN或SSD,其回归分支与分割分支共同作用才能得到候选框,分割分支的score map上的每个像素点值决定了回归分支中某几个框是否是有效的(目标框还是背景框)。而这篇文章的分割分支和回归分支除了共用特征外,以及最后把损失都加到损失层外,两个分支是完全独立的!也就是说,回归分支可以换成任何一个可以生成候选框的目标检测分支(RPN,SSD,甚至Faster R-CNN),分割分支可以换成任何一个可以生成目标置信概率图的分支,而把这两个分支加上最后的综合打分就可以让分割分支去帮助目标检测分支进一步过滤噪声(但对框的生成没有影响)。这种框架是把目前的两大类文字检测方法(基于目标检测的框架,和基于分割的框架)综合起来,可以提高检测精度。
问题搜集
- 为什么要用position-sensitive segmentation?从结果来讲,和普通的segmentation而言,到底好在哪里?是否是更适合各种粒度的文字(字符,单词,文本行)?
- 文章中用角点检测来检测文字和一般用目标检测的方法来检测文字,其优势和劣势在哪里?
- 优势
- 角点检测里每个角点都是独立的,所以在多个特征层上的detection的角点可以全部放到一个集合里再去两两组合获得文字框,而不采用每个特征层单独做直接得到文字框后再多层融合。这样好处在于,同一个框的不同角点可以是从不同的特征层上检测到的,即使在某一层上某个角点漏了,但有其他层可以帮忙将其找回来。
- 角点检测不用考虑方向性,所以可以用任何一般的目标检测框架而无需修改(加方向参数等)直接用于检测角点。
- 角点检测不用考虑文字框的长宽比大小,对于类似RPN等基于anchor的其defaut box的长宽比和scale不好设置,尤其针对长文本,角点检测则不用考虑这个问题。
- 可能潜在的问题
- 如果角点很多,那么这种两两组合的可能性很多,使得检测框特别多,对后续nms等压力较大。
- 由于任意两个角点都组合,所以可能导致很多无关的框、没有意义的框都被当做候选框(比如从左上顶点和右下顶点组成的框)。
- 我认为文章中疑问或者有问题的点
- Corner Point Prediction的offset输出没有必要是4维的,因为已知是正方形的情况下,只需x1,y1,s三维就好了(w = h = s)。
- 部分存在歧义,没有说清楚:We determine the relative position of a rotated rectangle by the following rules: 1) the x-coordinates of top left and bottom-left corner points must less than the x coordinates of top-right and bottom-right corner points; 2)the y-coordinates of top-left and top-right corner points must less than the y-coordinates of bottom-left and bottom right corner points.
实验结果

- 深度框架:Pytorch
- 结果与速度说明
- Nvidia Titan Pascal GPU
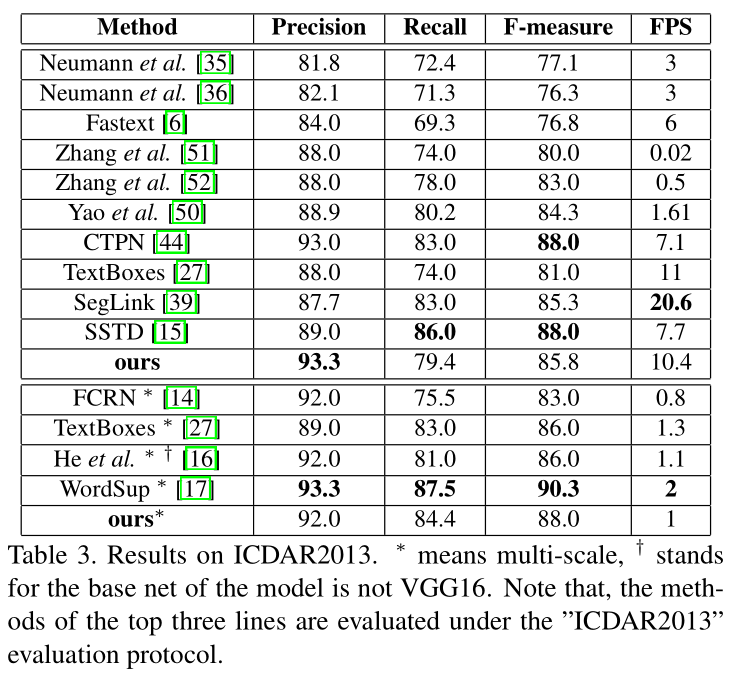
- ICDAR2013:图像大小resize成512 * 512,100ms/每张图,F值=85.5%/88.0%(多尺度)。
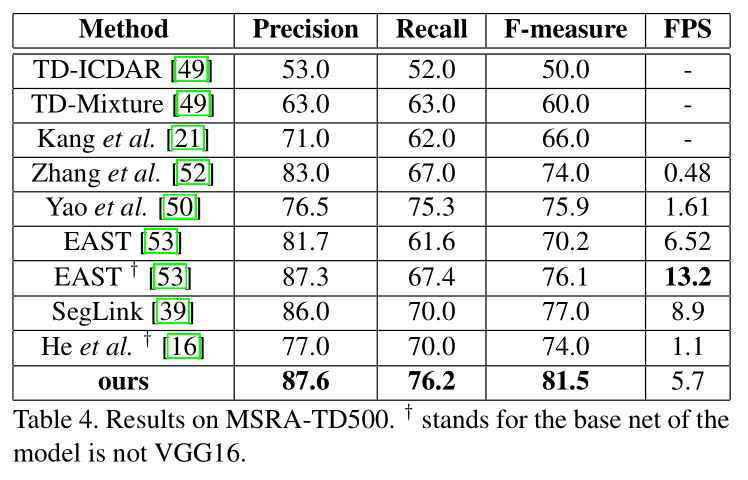
- MSRA-TD500:图像大小768 * 768,5.7FPS,F值=81.5%。
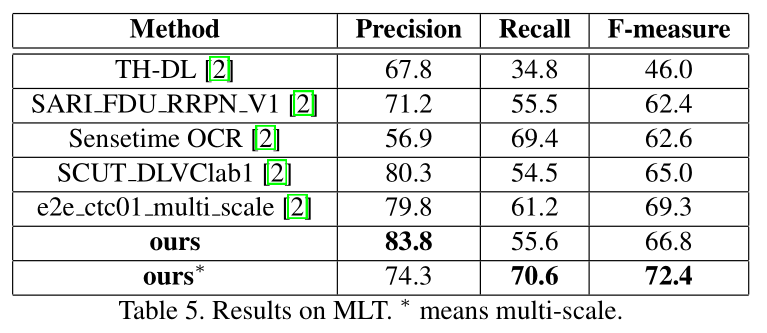
- MLT:768 * 768,F值=72.4%。
- ICDAR2015:768 * 1280,1FPS,F值= 84.3%。
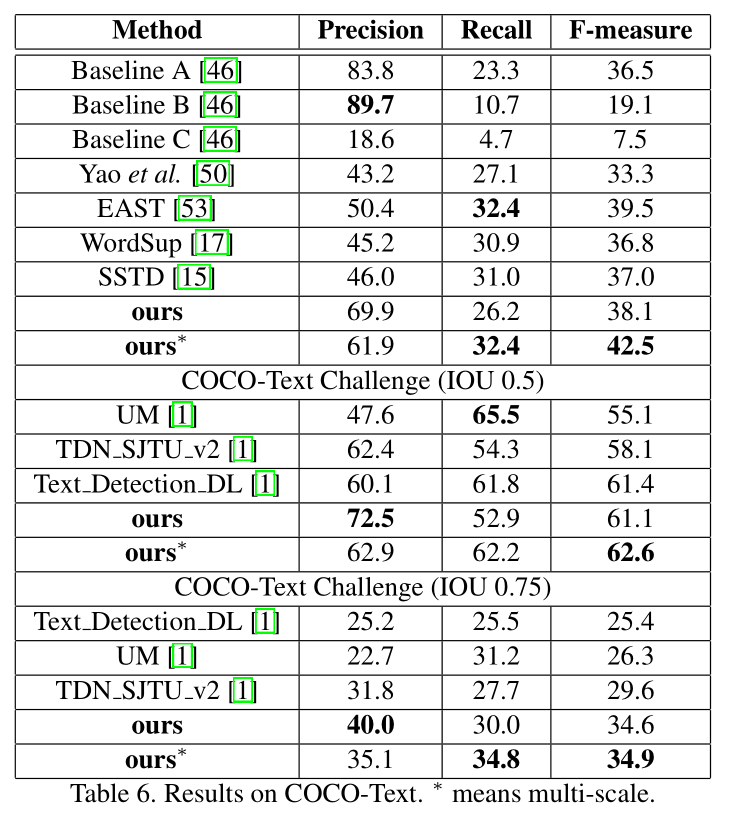
- COCO-Text:768 * 768,IOU=0.5,F值=42.5%。
- ICDAR2013
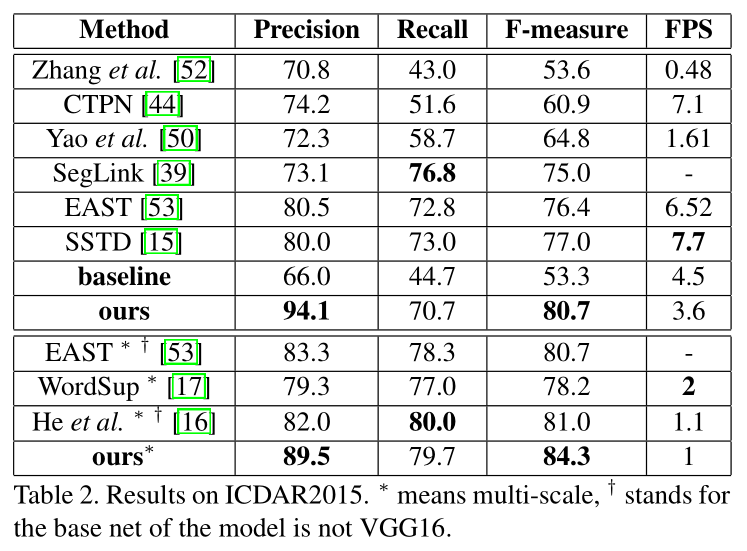
- ICDAR2015
- MSRA-TD500
- COCO-Text
- MLT
总结
- 用角点检测来做目标检测问题很有新意。
- Position-sensitive segmentation和一般的segmentation不太一样,虽然不是完全理解用这个的原因(融合位置信息?)。
- 做一次分割,再做一次目标检测,两个共同来打分,这个思路很有意思,不管是用什么做分割或检测,不管分割和检测是否共用网络基础结构,不管分割和检测之间是否有关系,这个框架都很可取。