
应用
语音唤醒,涉黄、涉暴、涉毒、涉堵图片检索,
相关工作
Attribute CNN:使用神经网络学习单词图像和属性表示间的映射。该方法的缺点是神经网络在训练分布外存在过度置信。即使Attribute CNN方法在许多常见的基准数据集中展示了卓越的性能,但是这是以需要训练数据为代价的。有些方法试图通过迁移学习和合并合成数据的方法来缓解数据问题,但是对于任何基于机器学习的方法来说,具有代表性的训练数据的必要性仍然是与生俱来的。
embedded attributes:属性嵌入和单词图像间的映射通过一系列的SVM学习到。这就允许将单词图像和字符串映射到一个常见的子空间,在这个子空间中,检索问题可以通过比较属性向量间的距离解决。
概率检索模型PRM:当在高维空间中,余弦相似度和欧氏距离无法提供一个鲁棒的距离度量的时候,PRM给出了查询和估计属性向量间的概率描述。
不同点
是否去做 segmentation-based 或者 segmentation-free 字定位
对于基于分割的字定位,假设可以利用已分割的单词图像,当面对现实生活中的实际问题时,这是一个不现实的猜想。而不需要分割的字定位只需要原始手稿页的图像。
基于分割的方法需要将文档页面分割成单独的单词图像,这通常不是一个容易解决的问题;如Attribute CNNs、embedded attributes。无分割方法并没有提出这一要求,而是联合解决检索和分割问题。
基于分割的字定位:PHOCNet,Embed attributes
无分割的字定位:Ctrl-F-Net
是否查询是一个手动裁剪的单词图像(QbE)还是单词字符串(QbS)
QbS 经常是优先选择,因为它不需要在搜索更多的情况之前,找到正在寻找的样例。
字定位的优先选择几乎总是无分割的QbS字定位
Word Spotting使文档图像可搜索。相比于文本识别来说,搜索功能是直接实现的,而不是一个复杂任务的副产品,因而是有效的。对于历史文档,自动分割是具有挑战的,由于写作风格的高可变性、文档布局、油墨与纸张的视觉外观。分割的方法在现代文档图像中很成功,如投影特征或连通分量,但是对于历史文档可能会失效,这些方法必须手工的调整到文档集合的特性。
只建立在连通分量上的文本检测器,有两个缺点。首先,检测器依赖于文档图像二值化,在历史文档图像中,由于褪色的墨水、低对比度和非均匀背景使得二值化变得困难,从而使检测不精确。其次,从连通分量中获得单词假设是困难的。因为连通分量只表示单词部分、单个单词或者多个单词,需要启发式的策略来合并连通分量。
联合解决分割与检索的字定位方法被称为无分割的方法。
CVPR2019
- An Alternative Deep Feature Approach to Line Level Keyword Spotting
Retsinas G, Louloudis G, Stamatopoulos N, et al. An Alternative Deep Feature Approach to Line Level Keyword Spotting[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 12658-12666.
作者:George Retsinas, Georgios Louloudis, Nikolaos Stamatopoulos, Giorgos Sfikas, Basilis Gatos
被引用次数:0
数字文档中关键字检索的深度特征方法,高效、存储要求低。
NCSR “Demokritos”、希腊国立雅典理工大学、希腊约阿尼纳大学。
ICDAR2017
- Evaluating word string embeddings and loss functions for CNN-based word spotting
Sudholt S, Fink G A. Evaluating word string embeddings and loss functions for CNN-based word spotting[C]//2017 14th iapr international conference on document analysis and recognition (icdar). IEEE, 2017, 1: 493-498.
作者: Sebastian Sudholt, Gernot A. Fink
被引用次数:26 - Ensembles for Graph-Based Keyword Spotting in Historical Handwritten Documents
Stauffer M, Fischer A, Riesen K. Ensembles for graph-based keyword spotting in historical handwritten documents[C]//2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2017, 1: 714-720.
作者: Michael Stauffer, Andreas Fischer, Kaspar Riesen
被引用次数:10
概要: - Word Hypotheses for Segmentation-free Word Spotting in Historic Document Images
Rothacker L, Sudholt S, Rusakov E, et al. Word hypotheses for segmentation-free word spotting in historic document images[C]//2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2017, 1: 1174-1179.
作者: Leonard Rothacker, Sebastian Sudholt, Eugen Rusakov, Matthias Kasperidus, Gernot A. Fink
被引用次数:9
概要:本文提出了一种无分割的字定位方法,将极值区域ER框架与TPP-PHOCNet相结合。首先针对于确定的文档图像区域预测得分,这些得分反映了单个区域是否包含文本。然后用极值区域ER对这些得分的不确定性进行明确的建模。ER方法生成了单词边界框的假设。接着,使用TPP-PHOCNet预测PHOC表示。最后,通过一个最近邻搜索进行字定位。使用了三种生成局部文本得分的方法:(1)SIFT对比得分;(2)局部区域分类得分(LRC);(3)局部单词区域得分(AAM-PHOCNet)。在GW和ICFHR 2016 KWS比赛数据集(Botany和Konzilsprotokolle)上实现了和最好的方法相媲美的结果。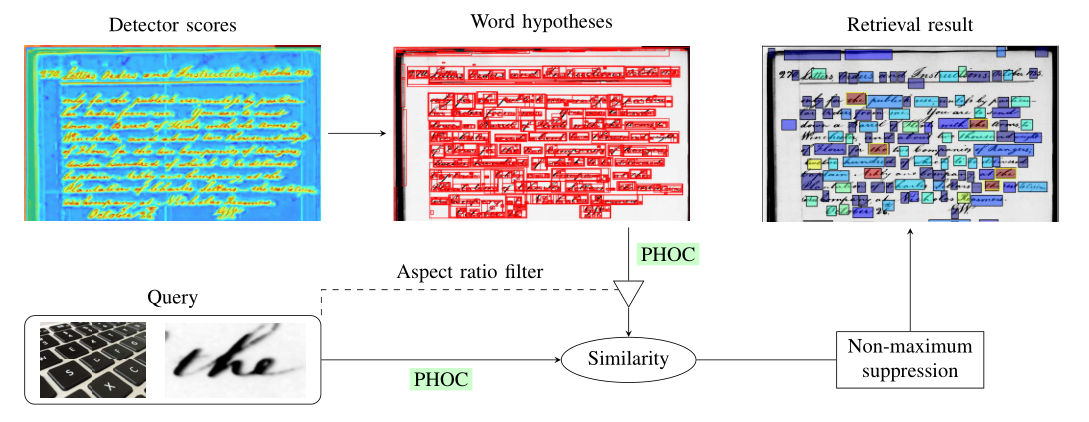
- LSDE: Levenshtein Space Deep Embedding for Query-by-string Word Spotting
Gómez L, Rusinol M, Karatzas D. Lsde: Levenshtein space deep embedding for query-by-string word spotting[C]//2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2017, 1: 499-504.
作者: Lluís Gómez, Marçal Rusiñol, Dimosthenis Karatzas
被引用次数:7 - Query-by-Online Word Spotting Revisited Using CNNs for Cross-Domain Retrieval
Sudholt S, Rothacker L, Fink G A. Query-by-online word spotting revisited: Using cnns for cross-domain retrieval[C]//2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2017, 1: 481-486.
作者: Sebastian Sudholt, Leonard Rothacker, Gernot A. Fink
被引用次数:2 - Assisted transcription of historical documents by keyword spotting: a performance model
Santoro A, De Stefano C, Marcelli A. Assisted transcription of historical documents by keyword spotting: a performance model[C]//2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2017, 1: 971-976.
作者: Adolfo Santoro, Claudio De Stefano, Angelo Marcelli
被引用次数:2 - Nonlinear Manifold Embedding on Keyword Spotting using t-SNE
Retsinas G, Stamatopoulos N, Louloudis G, et al. Nonlinear manifold embedding on keyword spotting using t-SNE[C]//2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2017, 1: 487-492.
作者: George Retsinas, Nikolaos Stamatopoulos, Georgios Louloudis, Giorgos Sfikas, Basilis Gatos
被引用次数:1 - R-PHOC: Segmentation-Free Word Spotting using CNN
Ghosh S K, Valveny E. R-PHOC: Segmentation-Free Word Spotting using CNN[C]//2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2017, 1: 801-806.
作者: Suman Ghosh, Ernest Valveny
被引用次数:1
ICDAR2019
- Training-Free and Segmentation-Free Word Spotting using Feature Matching and Query Expansion
Vats E, Hast A, Fornés A. Training-Free and Segmentation-Free Word Spotting using Feature Matching and Query Expansion[C]//International Conference on Document Analysis and Recognition (ICDAR). 2019.
作者: Ekta Vats, Anders Hast and Alicia Fornés
被引用次数: - KeyWord Spotting using Siamese Triplet Deep Neural Networks
Eglin V, Serdouk Y, Bres S, et al. KeyWord Spotting using Siamese Triplet Deep Neural Networks[C]. 2019.
作者: Yasmine Serdouk, Véronique Eglin and Stéphane Bres
被引用次数: - A Multi-oriented Chinese Keyword Spotter Guided by Text Line Detection
作者: Pei Xu, Shan Huang, Hongzhen Wang and Hao Song
被引用次数:
- Exploring Confidence Measures for Word Spotting in Heterogeneous Datasets
Wolf F, Oberdiek P, Fink G A. Exploring Confidence Measures for Word Spotting in Heterogeneous Datasets[J]. arXiv preprint arXiv:1903.10930, 2019.
作者: Fabian Wolf, Philipp Oberdiek and Gernot Fink
被引用次数: - Can One Deep Learning Model Learn Script-Independent Multilingual Word-Spotting?
Eglin V, Serdouk Y, Bres S, et al. KeyWord Spotting using Siamese Triplet Deep Neural Networks[C]. 2019.
作者: Mohammed Al-Rawi, Ernest Valveny and Dimosthenis Karatzas
被引用次数:0
作者:
被引用次数: