

TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes
KeyWords Plus: ECCV2018 Curved Text
paper:https://arxiv.org/abs/1807.01544
reference: Long S, Ruan J, Zhang W, et al. Textsnake: A flexible representation for detecting text of arbitrary shapes[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 20-36.
Github: https://github.com/princewang1994/TextSnake.pytorch
背景
近年来,从自然场景中提取文本信息,即场景文本检测与识别,成为了学术研究的热点。究其原因有二,应用前景和学术价值。一方面,场景文本检测与识别在一系列的实际应用中发挥着日益重要的作用,比如场景理解,产品搜索,自动驾驶等;另一方面,场景文本自身的独特属性使其有别于一般物体。
作为文本信息提取的前提条件之一,文本检测在深度神经网络和大型数据集的助力之下,取得了长足进展,出现了大量创新性工作,并在基准数据集上取得了优异的表现。
但是,现有大多数的文本检测方法有一个共同的假设:文本实例的形状大体上是线性的,因此可以采用相对简单的表征(轴对齐矩形,旋转矩形,四边形)去描述它们。尽管存在不少进步,但是在处理不规则形状的文本实例时,依然会暴漏出短板。如图 1 所示,对于带有透视变形(perspective distortion)的曲形文本(curved text)来讲,传统的表征方法在精确估计几何属性方面显得力不从心。
设计思想
事实上,曲形文本的情况在现实世界中很常见。本文提出一种更为灵活的表征,可以很好地拟合任意形状的文本,比如水平文本,多方向文本,曲形文本。这种表征通过一系列有序、彼此重叠的圆盘(disk)描述文本,每个圆盘位于文本区域的中心轴上,并带有可以变化的半径和方向。由于其在适应文本结构多样性方面的优异表现,就像蛇一样改变形状适应外部环境,该方法被命名为 TextSnake。文本实例的几何属性(比如中心轴点,半径,方向)则通过一个全卷积网络(FCN)进行评估。
除了 ICDAR 2015 和 MSRA-TD500 之外,TextSnake 的有效性还在 Total-Text 和 SCUT-CTW1500 (两个新公布的针对曲形文本的数据集)上获得了验证,并取得了当前最优的表现;此外,该方法还在水平文本和多方向文本上超越先前方法,即使是在单一尺度测试模式之下。具体而言,TextSnake 获得显著提升,在 Total-Text 数据集上 F-measure 超越基线 40%。
总结一下,本文贡献主要有 3 个方面:(1)本文提出一种灵活而通用的表征,可用于任意形状的场景文本;(2)基于这一表示,本文提出一种有效的场景文本检测方法;(3)该方法在包含若干个不同形式(水平,多方向,曲形)的文本实例数据集上取得了当前最优的结果。
方法
表征
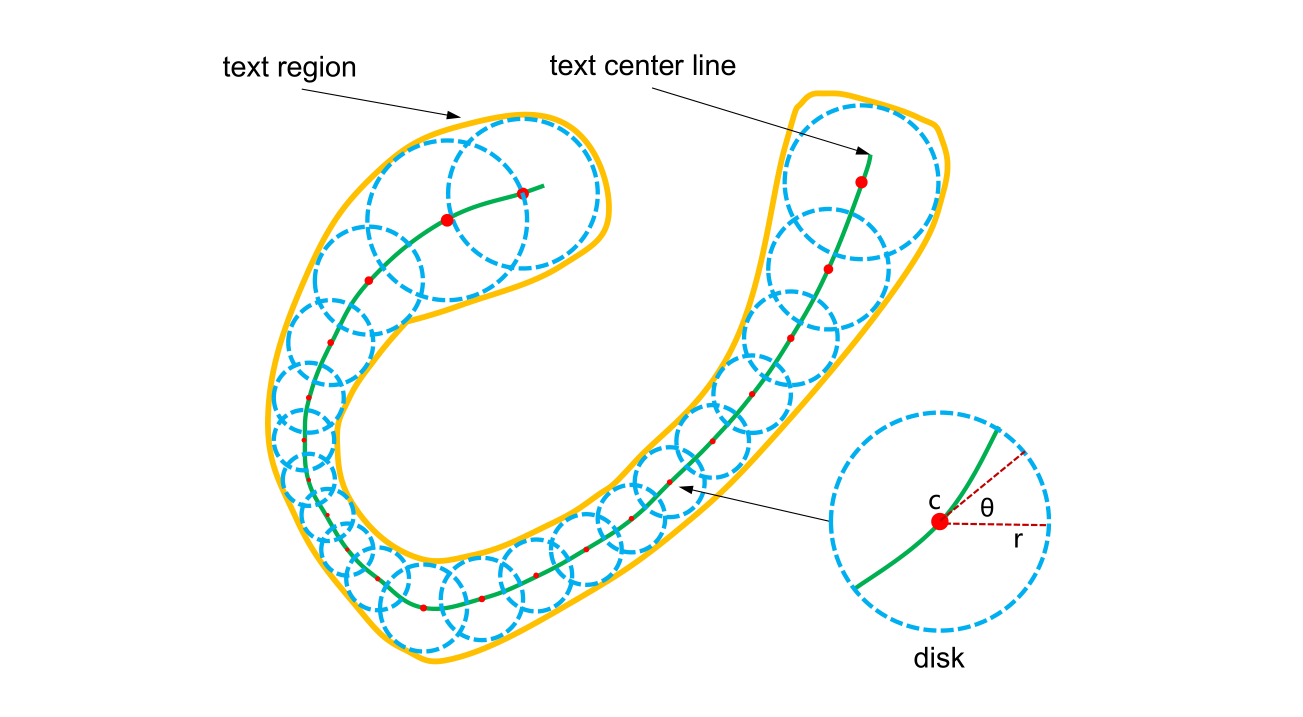
TextSnake 将一个文本区域(黄色)表征为一系列有序而重叠的圆盘(蓝色),其中每个圆盘都由一条中心线(绿色,即对称轴或骨架)贯穿,并带有可变的半径 r 和方向 θ 。直观讲,TextSnake 能够改变其形状以适应不同的变化,比如旋转,缩放,弯曲。
从数学上看,包含若干个字符的文本实例 t 可被看作是一个序列 S(t) 。S(t) = {D_0,D_1,··· ,D_i,··· ,D_n} ,其中 D_i 表示第 i 个圆盘,n 表示圆盘的数量。每个圆盘 D 带有一组几何属性, r 被定义为 t 的局部宽度的一半,方向 θ 是贯穿中心点 c 的中心线的正切。由此,通过计算 S(t) 中圆盘的重合,文本区域 t 可轻易被重建。
注意,圆盘并非一一对应于文本实例的字符。但是圆盘序列的几何属性可以改正不规则形状的文本实例,并将其转化为对文本识别器更加友好的矩形等。
### Pipeline

为检测任意形状的文本,本文借助 FCN 模型预测文本实例的几何属性。基于 FCN 的网络预测文本中心线(TCL),文本区域(TR)以及几何属性(包括 r,cosθ,sinθ)的分值图。由于 TCL 是 TR 的一部分,通过 TR 而得到 Masked TCL。假定 TCL 没有彼此重合,需要借助并查集(disjoint set)执行实例分割。Striding Algorithm 用于提取中心轴点,并最终重建文本实例。
### 架构
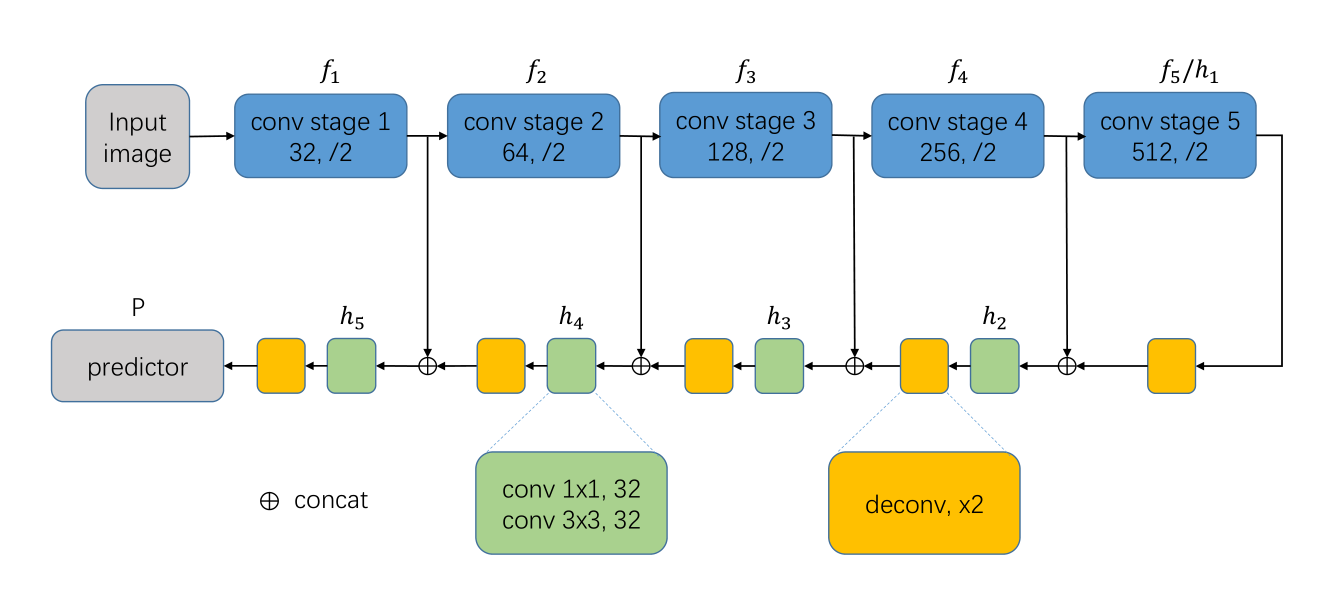
在 FPN 和 U-net 的启发下,本文提出一个方案,可逐渐融合来自主干网络不同层级的特征。主干网络可以是用于图像分类的卷积网络,比如 VGG-16/19 和 ResNet。这些网络可以被分成 5 个卷积阶段(stage)和若干个额外的全连接层。本文移除全连接层,并在每个阶段之后将特征图馈送至特征融合网络。出于与其他网络进行公平而直接对比的考虑,本文选择 VGG-16 作为主干网络。
### 预测
馈送之后,网络输出 TCL,TR 以及几何图。对于 TCL 和 TR,阈值分别设为 T_tcl 和 T_tr;接着,TCL 和 TR 的交叉点给出 TCL 最后的预测。通过并查集,可以有效把 TCL 像素分割进不同的文本实例。最后,Striding Algorithm 被设计以提取用来表示文本实例形状和进程(course)的有序点,同时重建文本实例区域。
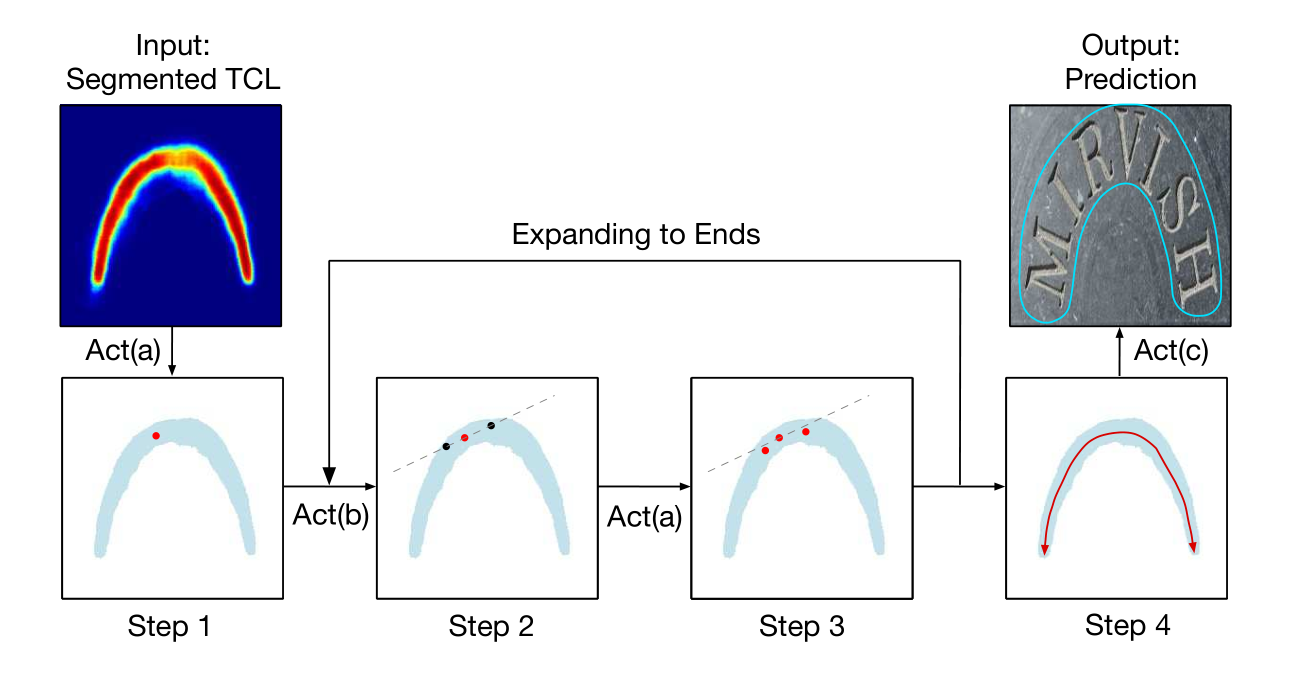
Striding Algorithm 的流程如图 5 所示。它主要包含 3 个部分:Act(a)Centralizing ,Act(b) Striding 和 Act(c)Sliding 。首先,本文随机选择一个像素作为起点,并将其中心化。接着,搜索过程分支为两个相反的方向——striding 和 centralizing 直到结束。这一过程将在两个相反方向上生成两个有序点,并可结合以生成最终的中心轴,它符合文本的进程,并精确描述形状。
## 实验
在标准数据集上评估了 TextSnake 的场景文本检测能力,并与先前同类方法进行了对比,数据集主要有 SynthText,TotalText,CTW1500,ICDAR 2015,MSRA-TD500。
### Total-Text & CTW1500
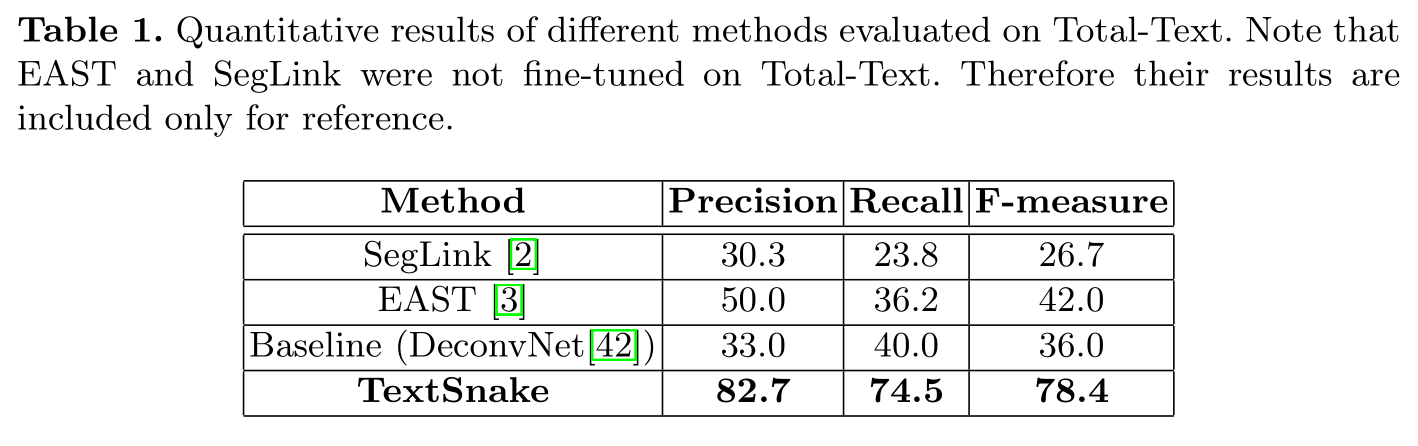
Total-Text & CTW1500 数据集上展开的是有关曲形文本的实验,其优异表现证明了TextSnake 在处理曲形文本方面的有效性。表 1 & 表 2 分别是两个数据集上不同方法的量化结果。

ICDAR 2015
ICDAR 2015 上进行的是有关偶然场景文本的实验。在单一尺度测试中,TextSnake 超越了绝大多数现有方法(包括那些在多尺度中评估的方法),这证明了 TextSnake 的通用性以及已经可用于复杂场景的多方向文本。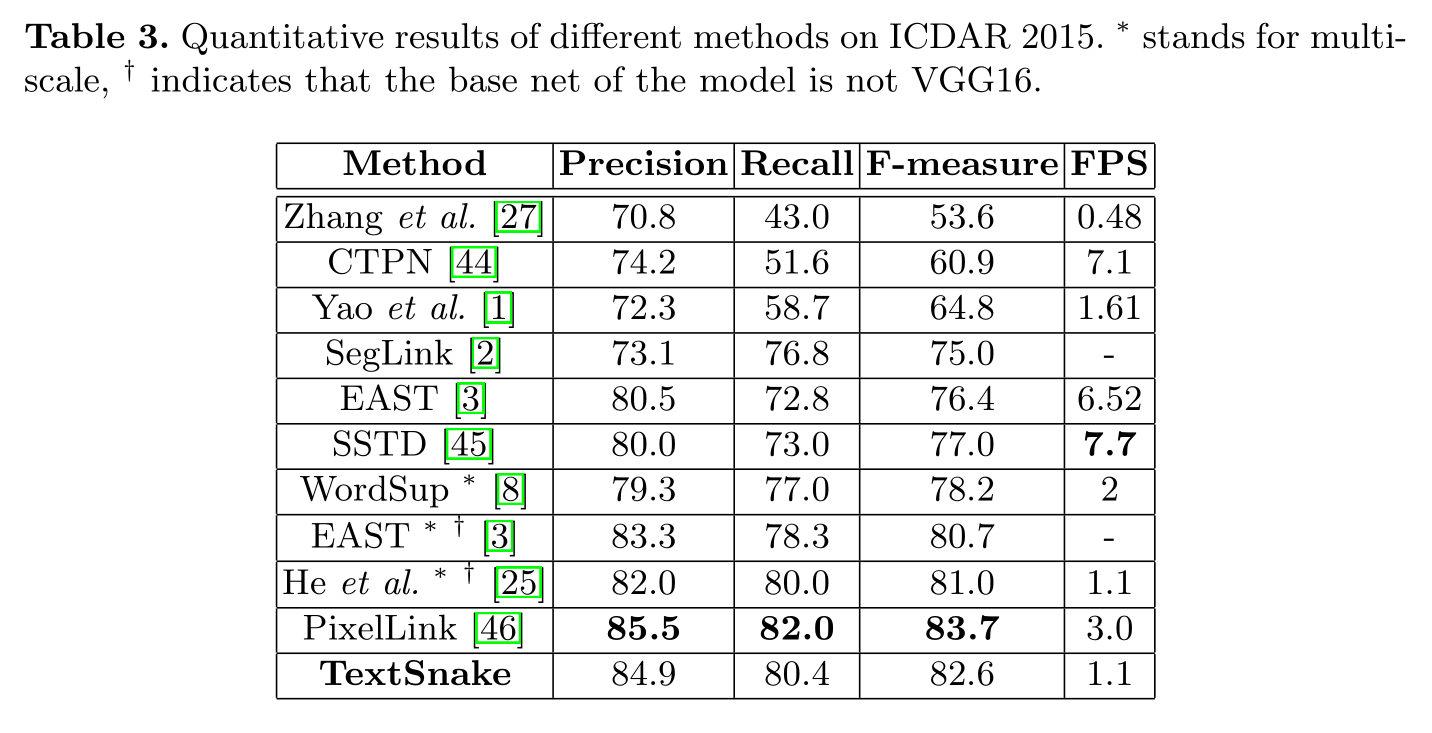
MSRA-TD500
本文在 MSRA-TD500 上进行有关长直文本线的实验。其中 TextSnake 的 F 值 78.3% 优于其他方法。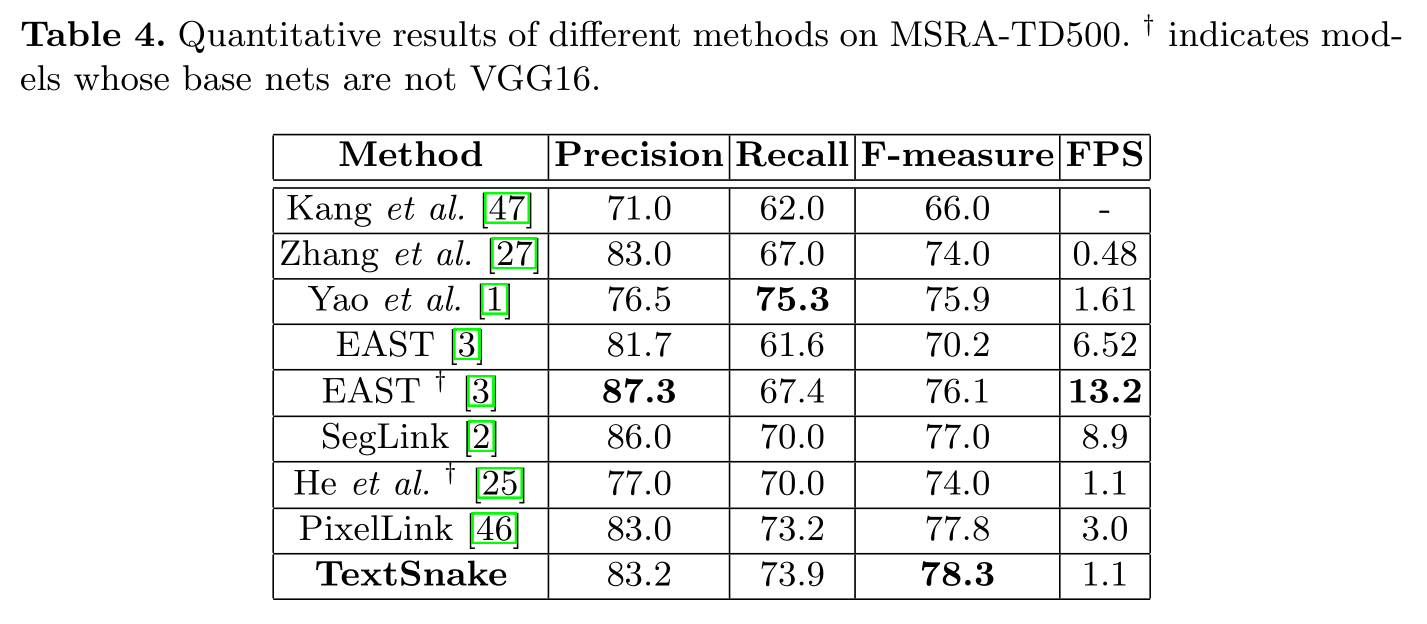
分析与讨论
TextSnake 之所以出类拔萃,在于其对文本实例的进程及形状的精确描述具有预测的能力(见图 8)。而这一能力来自对 TCL 进行的预测,它要比整个文本实例窄很多。这样做有两个优势:1)纤细的 TCL 可以更好地描述进程和形状;2)TCL 彼此不会重叠,因此实例分割得以一种十分简单而直接的方式完成,由此简化 pipeline。
此外,本文还利用局部几何属性描绘文本实例的结构,把已预测的曲形文本实例转化为规范形式,这大大减轻了后续识别阶段的工作。
为进一步验证 TextSnake 的泛化能力,本文在不包含曲形文本的数据集上进行了训练和微调,并在含有曲形文本的两个数据集上做了评估。在没有曲形文本微调的情况下,TextSnake 依然表现良好,并显著超越其他三个竞争者 SegLink,EAST 和 PixelLink,这要归功于 TextSnake 作为灵活表征的优秀泛化能力(见表 5)。
TextSnake 把文本看作一个局部元素的集合,而不是一个整体,并通过整合元素的方式做决策。因此,TextSnake 最后的预测可以保持文本进程和形状的最大量信息,这是该算法胜任不同形状文本实例的主要原因。
结论
本文提出一种全新而灵活的表征——TextSnake,可以描述任意形状的场景文本,包括水平文本,多方向文本和曲形文本。基于 TextSnake 的文本检测新方法已在两个新开源的曲形文本数据集(Total-Text 和 SCUT-CTW1500)和两个经典数据集(ICDAR 2015 和 MSRA-TD500)上取得了当前最优或有竞争力的结果,证实了该方法的有效性。未来,本文作者将尝试开发一个针对任意形式文本的端到端识别系统。