

Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes
KeyWords Plus: CVPR2019 Curved Text
paper:https://arxiv.org/abs/1904.06535
reference: Zhang C, Liang B, Huang Z, et al. Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes[J]. arXiv preprint arXiv:1904.06535, 2019.
Github: 未开源
简介
这是百度和厦门大学合作的一篇文章。由于受CNN感受野的限制以及用于描述文本的类似矩形框或者四边形这样的简单的表示方法,当处理更加有挑战的文本实例时,比如极其长的文本和任意形状的文本,之前的一些方法就不适用了。而本文提出的这种方法,正是为了解决这两个问题。
本文提出了一种文本检测器,即LOMO(Look More Than Once),它可以逐步地调整文本(或者换句话说,不止看一次)。LOMO由直接回归器(DR)、迭代细化模块(IRM)和形状表示模块(SEM)组成。首先,DR分支生成四边形的文本proposals。接下来,IRM基于提取的初步proposals的特征块,通过迭代细化逐步感知整个长文本。最后,通过考虑文本实例的几何属性,包括文本区域、文本中心线和边界偏移,引入SEM来得到更加精确的不规则的多边形的文本表示。
论文主要贡献
(1)提出了一个迭代细化模块(IRM),它改善了长文本检测的性能。
(2)引入实例级形状表示模块(SEM),用于解决任意形状的场景文本的检测问题。
(3)加入迭代细化模块和形状表示模块的LOMO可以以端到端的方式训练,并在几个包括不同形式的文本实例(有向的、长的、多语言的和弯曲的)的基准数据集上实现了最佳的性能。
网络结构
(1)将图像输入到backbone中,抽取 DR, IRM 和 SEM 三个分支的共享特征图。backbone用的是ResNet50 + FPN,对ResNet50中的阶段2,阶段3,阶段4和阶段5的特征图进行特征融合,得到大小是输入图像的1/4,通道是128的特征图。并由之后的DR,IRM和SEM三个分支共享该特征图。
(2)采用类似 EAST 和 Deep Regression 的一个direct regression network作为 DR 分支,以一种逐像素的方式去预测单词或文本行的四边形。通常,由于感受野的限制,DR分支很难检测到长文本。如图2(2)所示的蓝色四边形。
(3)IRM可以从DR或其自身的输出迭代地细化输入proposals,以使初步文本proposals被完善,以更完整地覆盖文本实例,更接近真实边界框。如图2(3)所示的绿色四边形。
(4)为了获得文本的紧凑表示,尤其是不规则的文本,因为四边形的建议形式会覆盖太多的背景区域,通过学习文本的几何性质包括文本区域,文本中心线和边界偏移(中心线和上/下边界线之间的距离),SEM会重建文本实例的形状表示。如图2(4)所示的红色四边形。
Direct Regressor(DR):直接回归DR–>文本/非文本分类和位置回归
DR模块采用的是一个fully convolutional sub-network。基于共享特征图,计算文本/非文本置信度、和包含该正样本像素的矩形的4个角点的偏移量。DR分支的损失函数由两部分组成:文本/非文本分类和位置回归。
将文本/非文本分类视为在1/4下采样分数图上的二值分割。
第一部分文本分类的损失函数使用的是scale-invariant dice-coefficient函数,用于提升 DR 的尺度泛化能力。其中y是0/1标签图,y^是预测分数图,sum是2D空间上的累积函数。此外,w是二维权重图。正位置的值通过将它们所属的四边形的短边分开的归一化常数l来计算,而负位置的值被设定为1.0。在实验中将常数l设置为64。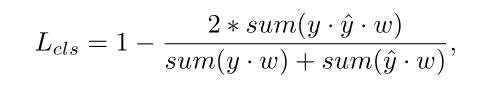
第二部分位置回归的损失函数采用的是smooth L1 loss。将这两项结合到一起,DR的整个损失函数可以表示为: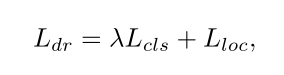
其中超参数λ平衡两个损失项,在实验中设置为0.01。
Iterative Refinement Module(IRM):迭代细化模块IRM
IRM的设计参考基于区域的物体检测,但只有边界框回归任务。使用RoI变换层来提取输入文本四边形的特征块,而不是RoI pooling层或RoI align层。与后两者相比,前者可以在保持纵横比不变的情况下提取四边形建议的特征块。
此外,靠近角点的位置可以在同一感受野内感知到更准确的边界信息。因此,引入角点注意力机制来回归每个角点的坐标偏移。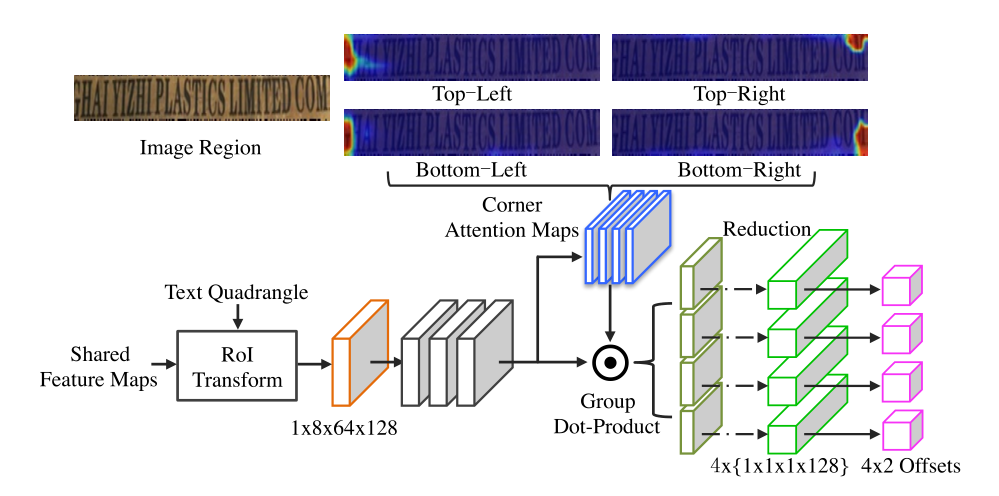
对于一个DR生成的文本四边形,将其与共享特征图一起输入到RoI变换层,获得1×8×64×128特征块。然后,三个3×3卷积层以进一步提取丰富的上下文信息fr。接下来,使用1×1卷积层和sigmoid层来学习4个角点的注意力图ma。每个角点注意力图上的值表示支持相应角点的偏移回归的贡献权重。
使用fr和ma,可以通过逐点生成和reduce_sum操作来提取4个角点回归特征(图3中绿色的4X{1X1X1X128}特征图):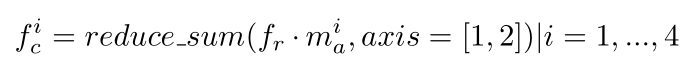
其中fci表示形状为1×1×1×128的第i个角点回归特征,mia是第i个角点注意力特征图。
最后,预测输入四边形和真值文本框之间的4个角点的偏移。
在训练阶段,保留来自于DR的K个初步的检测四边形。corner regression loss可以表示为: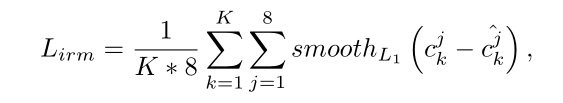
Shape Expression Module(SEM):形状表示模块SEM
SEM是完全卷积网络,随后是RoI变换层。学习文本的几何属性,包括文本区域、文本中心线和边界偏移(文本中心线和上/下文本边界线之间的偏移),以重建文本实例的精确形状表示。
文本区域是一个二值 mask, 里面的 foreground pixels (比如在多边形标注区域内部的)标记为 1,background pixels 标记为 0。
文本中心线 也是一个二值 mask ,不同的是,它是基于文本多边形标注的 side-shrunk version .
边界偏移 为四通道图, 在文本行图对应位置上的正响应区域内,具有有效的值。当中心线样本(红点)如图4(a)所示,绘制一条垂直于其切线的法线,该法线与上下边界线相交,得到两个边界点(即粉色和橙色)。对于每个红点,通过计算从其自身到其两个相关边界点的距离来获得4个边界偏移。
SEM 的结构如图4所示,RoI变换层提取的共享特征图上的特征块,之后是两个卷积阶段(每个阶段由一个上采样层和两个3×3卷积层组成),然后使用一个带有6个输出通道的1×1卷积层,用于回归所有文本属性映射。SEM 的目标函数定义如下,其中 Ltr 和 Ltcl 使用dice-coefficient loss,Lborder 使用smooth L1 loss: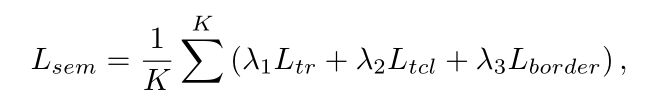
其中K表示保留IRM的文本四边形的数量,Ltr和Ltcl分别是文本区域和文本中心线的dice系数损失,Lborder是通过Smooth_L1损失计算。在实验中,权重λ1、λ2和λ3设定为0.01,0.01和1.0。
文本多边形生成
通过文本多边形生成策略来重建任意形状的文本实例表示。文本多边形生成策略包括三步:
(1)center line sampling: 在预测的文本中心线图上从左到右以等距离间隔采样n个点。
(2)border points generation: 基于采样中心线点,考虑同一位置由4个边界偏移图提供的信息,确定相应的边界点。通过顺时针连接所有的边界点,获得完整的文本多边形表示。
(3)polygon scoring: 计算多边形内的文本区域响应的平均值,作为新的 confidence score。
训练和推理
整个的损失函数表示为: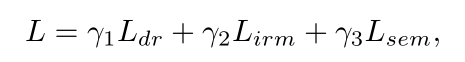
其中Ldr,Lirm和Lsem分别代表DR,IRM和SEM的损失。权重γ1,γ2和γ3在三个模块之间折衷,并且在实验中都设置为1.0。
Training:训练过程分为两个阶段,warming-up(预热) 和 fine-tuning(微调).
1)在 warming-up 阶段,使用合成数据集训练 DR 部分,迭代 10 epochs。通过这种方式,DR可以生成高召回的proposals,以涵盖实际数据中的大部分文本实例。
2)在 fine-tuning 阶段, 在真实数据集上 fine-tune 所有的三个分支,包括 ICDAR2015, ICDAR2017-RCTW, SCUT-CTW1500, Total-Text 和 ICDAR2017-MLT,迭代大约 10 epochs。IRM和SEM分支都使用由DR分支生成的相同提议。非极大值抑制(NMS)用于保留前K个提议。由于DR表现不佳,这将影响IRM和SEM分支的融合,在实践中用随机扰乱的GT文本四边形替换50%的前K个proposals。注意,IRM仅在训练期间进行一次细化。
Inference:
1)DR 生成四边形的得分图和几何图, 然后用 NMS 生成初步的文本建议。
2)文本建议和共享特征图全部输入到 IRM 中改善多次。
3)精确的四边形和共享特征图输入到 SEM 中,生成精确的文本多边形和置信度得分。
4)阈值 s 用于移除低置信度的多边形。在实验中将s设置为0.1。
数据集
ICDAR 2015
包含1000张自然场景图像用于训练和500张用于测试。真值是以单词级别的四边形(word-level quadrangle)标注的。
ICDAR2017-MLT
一个大规模的多语言(large scale multi-lingual)文本数据集,包括7200张训练图像、1800张验证图像和9000张测试图像。这个数据集包含来自于9种语言的场景文本图像。文本区域是以有四个顶点的四边形(4 vertices of the quadrangle)标注的。
ICDAR2017-RCTW
它包含8034张训练图像和4229张测试图像,这些图像上的场景文本是以中文或者英文打印的。多方向的单词和文本行(Multi-oriented words and text lines)是以四边形(quadrangles)标注的。
SCUT-CTW1500
包含1000张训练图像和500张测试图像。文本实例以有14个顶点的多边形标注。
Total-Text
一个curved text(曲线文本)基准数据集,包括1255张训练图像和300张测试图像。标注是单词级别(word-level)的。
实验
对于所有的数据集,随机裁剪文本区域并将它们统一缩放到512x512。被裁剪的图像区域将会按照四个方向(0◦、90◦、180◦、270◦)随机旋转。

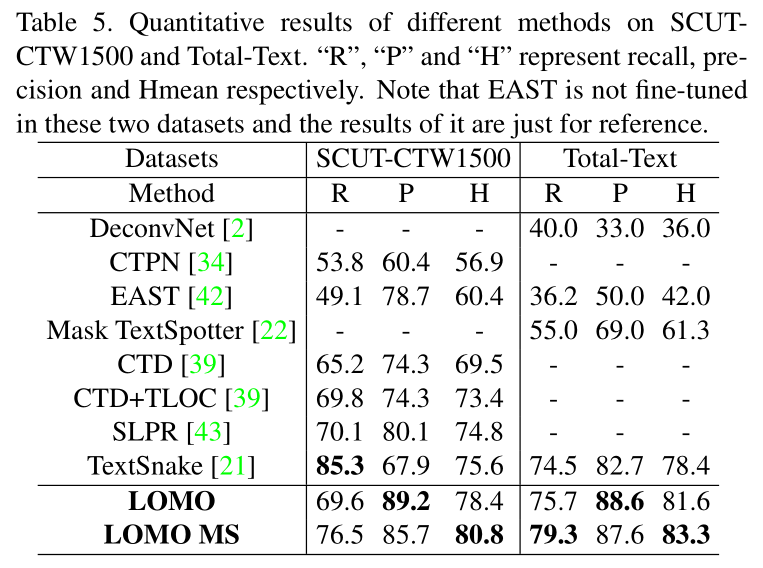
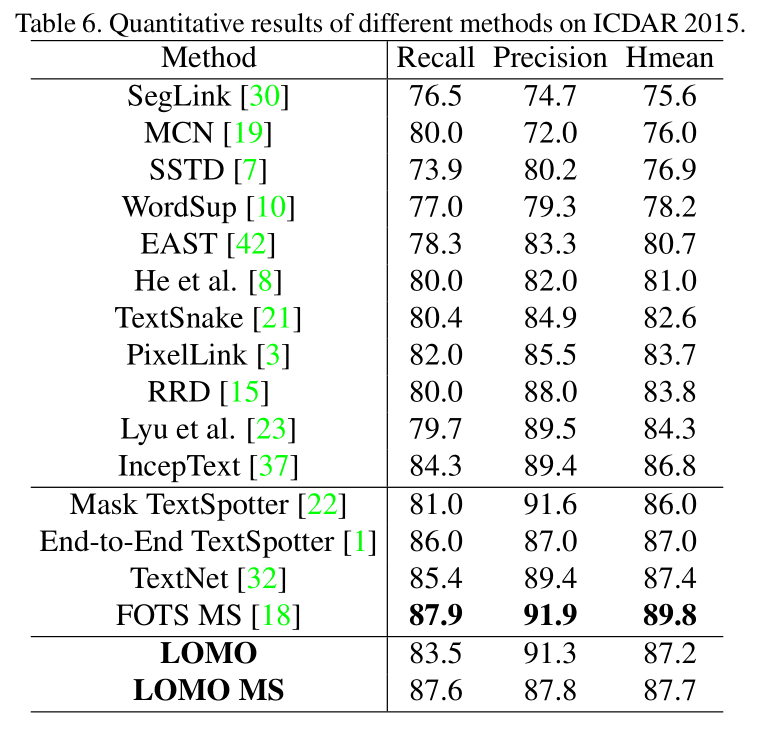

结论和未来的工作
这篇论文主要解决长文本和弯曲文本的检测问题,LOMO由 DR、IRM and SEM 三个模块组成。DR初步产生文本建议。IRM迭代式的调整DR生成的文本建议。SEM重建不规则文本的精确表示。