

Shape Robust Text Detection with Progressive Scale Expansion Network
KeyWords Plus: CVPR2019 Curved Text Face++
paper:https://arxiv.org/abs/1903.12473
reference: Wang W, Xie E, Li X, et al. Shape Robust Text Detection with Progressive Scale Expansion Network[J]. arXiv preprint arXiv:1903.12473, 2019.
Github(tensorflow): https://github.com/whai362/PSENet
Github(pytorch): https://github.com/WenmuZhou/PSENet.pytorch
Introduction
PSENet 分好几个版本,最新的一个是19年的CVPR,这是一篇南京大学和face++合作的文章,19年出现了很多不规则文本检测算法,TextMountain、Textfield等等。
1、论文创新点
- Propose a novel kernel-based framework, namely, Progressive Scale Expansion Network (PSENet)
- Adopt a progressive scale expansion algorithm based on Breadth-First-Search (BFS):
1) Starting from the kernels with minimal scales (instances can be distinguished in this step).
2) Expanding their areas by involving more pixels in larger kernels gradually.
3) Finishing until the complete text instances (the largest kernels) are explored.
这个文章主要做的创新点大概就是预测多个分割结果,分别是S1,S2,S3…Sn代表不同的等级面积的结果,S1最小,基本就是文本骨架,Sn最大,就是完整的文本实例。然后在后处理的过程中,先用最小的预测结果去区分文本,再逐步扩张成正常文本大小。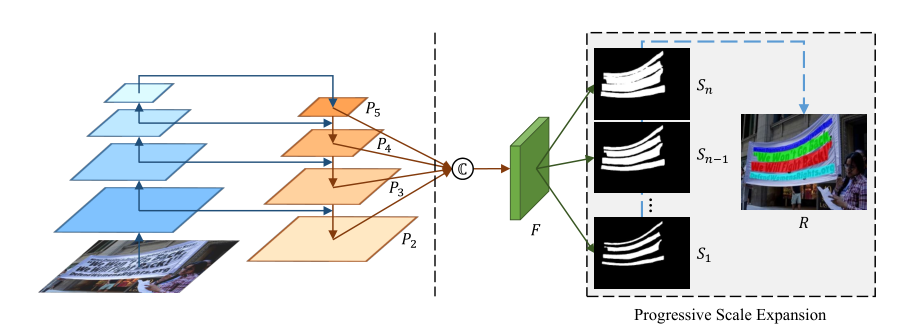
2、算法主体

We firstly get four 256 channels feature maps(i.e. P2, P3, P4, P5)from the backbone. To further combine the semantic features from low to high levels, we fuse the four feature maps to get feature map F with 1024 channels via the function C(·) as: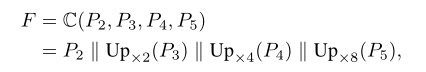
先backbone下采样得到四层的feature maps,再通过FPN对四层feature分别进行上采样2,4,8倍进行融合得到输出结果。
如上图所示,网络有三个分割结果,分别是S1,S2,S3.首先利用最小的kernel生成的S1来区分四个文本实例,然后再逐步扩张成S2和S3。
3、label generation
产生不同尺寸的S1….Sn需要不同尺寸的labels。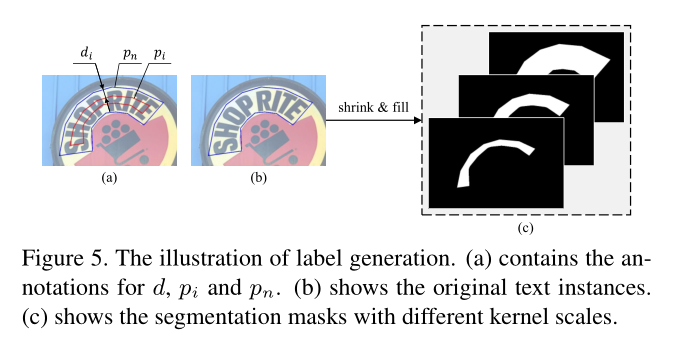
不同尺寸的labels生成如上图所示,缩放比例可以用下面公式计算得出: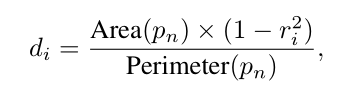
这个di表示的是缩小后mask边缘与正常mask边缘的距离,缩放比例rate ri可以由下面计算得出: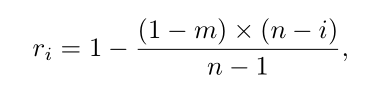
m是最小mask的比例,n在m到1之间的值,成线性增加。
4、Loss Function
Loss 主要分为分类的text instance loss和shrunk losses,L是平衡这两个loss的参数。分类loss主要用了交叉熵和dice loss。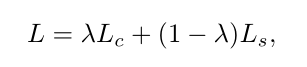
The dice coefficient D(Si, Gi) 被计算如下:
Ls被计算如下:
5、Datasets
TotalText
A newly-released dataset for curve text detection. Horizontal, multi-Oriented and curve text instances are contained in Total-Text. The benchmark consists of 1255 training images and 300 testing images.
CTW1500
CTW1500 dataset mainly consisting of long curved text. It consists of 1000 training images and 500 test images. Text instances are labelled by a polygon with 14 points which can describe the shape of an arbitrarily curve text.
ICDAR 2015
Icdar2015 is a commonly used dataset for text detection. It contains a total of 1500 pictures, 1000 of which are used for training and the remaining are for testing. The text regions are annotated by 4 vertices of the quadrangle.
ICDAR 2017 MLT
ICDAR 2017 MIL is a large scale multi-lingual text dataset, which includes 7200 training images, 1800 validation images and 9000 testing images. The dataset is composed of complete scene images which come from 9 languages.
6、Experiment Results
Implementation Details
All the networks are optimized by using stochastic gradient descent (SGD).The data augmentation for training data is listed as follows:
1) The images are rescaled with ratio {0.5, 1.0, 2.0, 3.0} randomly;
2) The images are horizontally flipped and rotated in the range [−10◦, 10◦] randomly;
3) 640 × 640 random samples are cropped from the transformed images.

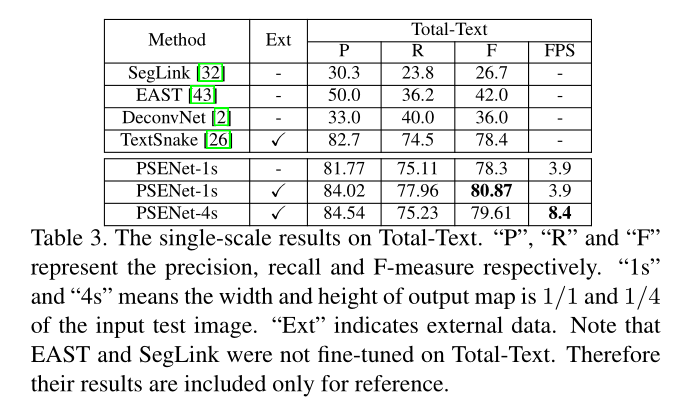



7、Conclusion and Future work
这个文章其实做的只是一件事情,就是用预测得到的小的mask区分文本,然后逐渐扩张形成正常大小的文本mask。