Pyramid Mask Text Detector
KeyWords Plus: CVPR2019 Quadrilateral Text
paper:https://arxiv.org/pdf/1903.11800.pdf
reference: Liu, Jingchao & Liu, Xuebo & Sheng, Jie & Liang, Ding & Li, Xin & Liu, Qingjie. (2019). Pyramid Mask Text Detector.
Github: 未开源
本文是商汤和香港中文大学联合发表并于 2019.03.28 挂在 arXiv 上,本文的方法在 ICDAR2017 MIT 数据集上,相比于之前最高的精确率提升了 5.83% 百分点,达到 80.13%;在 ICDAR2015 数据集上,提升了 1.34% 个百分点,达到 89.33%。
论文主要思想
本文提出了 Pyramid Mask 文本检测器,简称 PMTD。它主要做了如下工作:
- 提出了软语义分割的训练数据标签。与现有的基于 Mask RCNN 方法(文本区域内的像素标签为 0 或 1)不同,本文针对文本区域和背景区域提出了软语义分割(soft semantic segmentation),文本行区域内的像素标签值范围在 0-1 之间,不同位置的像素标签值是由其当前位置到文本边界框的距离决定的,这样做的好处是可以考虑训练数据的形状和位置信息,同时可以一定程度上缓解文本边界区域的一些背景干扰;
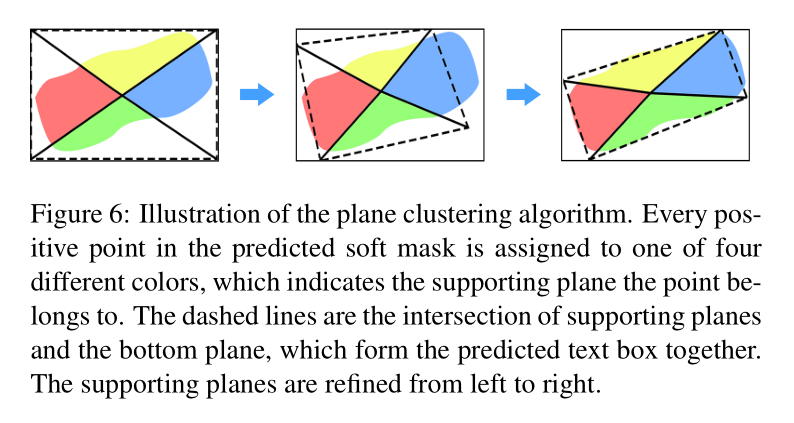
- 提出通过平面聚类的方法构建最终的文本行。通过像素坐标及对应像素点的得分构建 3D 点集合,然后通过金字塔平面聚类的迭代方法得到最终的文本行。

实验
文中做了两个实验:baseline 和 PMTD。baseline 是基于 Mask RCNN 的,主干提取特征网络采用的是 ResNet50,网络结构采用了 FPN。相比原生的 Mask RCNN,做了 3 方面修改:1)数据增广;2)RPN anchor;3)OHEM。
baseline存在的问题
- 没有考虑普通文本一般是四边形,仅按照像素进行分类,丢失了与形状相关的信息;
- 将文本行的四边形的标定转换为像素级别的 groundtruth 会造成 groundtruth 不准的问题;
- 在 Mask R-CNN 中是先得到检测的框,然后对框内的物体进行分割,如果框的位置不准确,这样会导致分割出来的结果也不会准确。
PMTD所做的改进
PMTD 是针对 baseline 中存在的问题提出的改进,主要包括:
- 网络结构的改进:PMTD 采用了更大的感受野来获取更高的准确率,为了获取更大的感受野,本文通过改变 mask 分支,将该分支中的前 4 个卷积层改成步长为 2 的空洞卷积,因为反卷积操作会带来棋盘效应,所以这里采用双线性采样+卷积层来替换反卷积层;
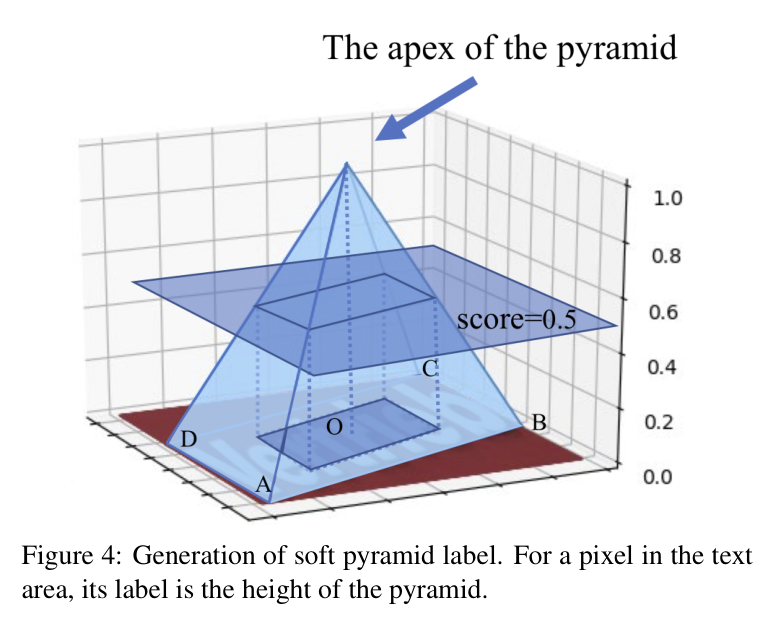
- 对于训练标签生成部分,使用了金字塔标签生成,具体做法是:文本行的中心点为金字塔的顶点(score=1),文本行的边为金字塔的底边,对金字塔的每个面中应该包含哪些像素点采用双线性插值的方法。
最终文本行的生成
文中使用了平面聚类的方法,用于迭代回归从已学习到的 soft text mask 寻找最佳的文本行的边界框。在具体操作时,可以看成与金字塔标签生成的反过程。